

The Essentials of System Availability

Just a guy who loves to write code and watch anime.
Introduction
System availability is an important measurement that shows how often a service or platform is working and available for users. Having high availability isn't only a technical need, but it's also essential for keeping users happy and the business running smoothly.
What is Availability?
Availability measures the proportion of time a system is operational and available to users.
For anyone subscribing to a service, especially those paying for it, the expectation is that this service will be available whenever needed, 24/7. Not meeting these expectations can cause users to be unhappy and can result in big money losses for the company.
High Availability
Certain systems demand exceptionally high availability due to the critical nature of their functions.
For example, a hospital's database system needs to be available all the time to get patient records. Any downtime could cause serious problems. Also, an airplane's control system must always work, because any failure could lead to terrible results.
Measuring Availability: The "Nines"
Availability is usually measured in "nines."
For instance, a system with 99.9% availability works 99.9% of the time during a specific period. This means it can be down for about 8.76 hours each year. Adding more nines makes the system more reliable, but also more complex and expensive.
Two Nines (99%): Allows for 3.65 days of downtime per year.
Three Nines (99.9%): Limits downtime to 8.76 hours per year.
Four Nines (99.99%): Reduces downtime to 52.56 minutes per year.
Five Nines (99.999%): Cuts downtime to just 5.26 minutes per year.
Service Level Agreements (SLA)
An SLA is an agreement that describes the expected service quality between a provider and a customer, often with specific availability goals. It's a way to officially promise to keep a certain level of availability.
Service Level Objectives (SLO)
While related to SLAs, SLOs are specific targets within those agreements, representing precise goals a service aims to achieve in terms of performance and reliability.
Achieving High Availability
To ensure high availability, systems must eliminate single points of failure, where the failure of a single component could bring down the entire service. This involves implementing redundancy, where multiple components can perform the same function, ensuring the system remains operational even if one component fails.
Redundancy and Load Balancing
Redundancy can be passive, with backup components waiting to take over in case of a failure, or active, where all components are operational simultaneously and share the workload.
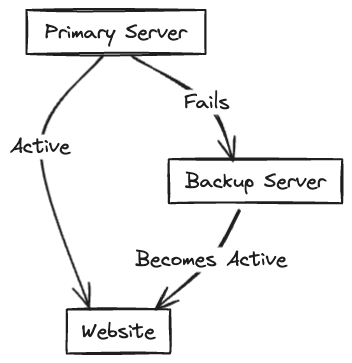
Passive Redundancy: Backup Server
Passive redundancy involves a standby system that activates only when the primary system fails.
For example, consider a website hosted on a primary server with a backup server updated nightly. The backup server remains idle until the primary server fails, at which point it takes over to ensure the website remains accessible.
What makes it passive? The backup server does nothing until the primary fails.
Active Redundancy: Load-Balanced Web Servers
Active redundancy involves multiple systems running concurrently, sharing the workload. An example is a website served by multiple web servers behind a load balancer. The load balancer distributes incoming traffic evenly across all servers, ensuring no single point of failure.
What makes it active? All servers are actively handling requests simultaneously.

Conclusion
Keeping a system available all the time is important for any service. This needs good planning and a strong system design. By using ideas like redundancy, companies can make sure their services are always open to users. This meets both user expectations and business requirements.




