

Practical Prompt Engineering Lessons
What We Learned Building with LLMs.
Just a guy who loves to write code and watch anime.
Introduction
This post is co-written with stonechat. We worked every day together during my time at Spawn. He was the first engineer at Spawn and built our entire chat. Insanely cracked.
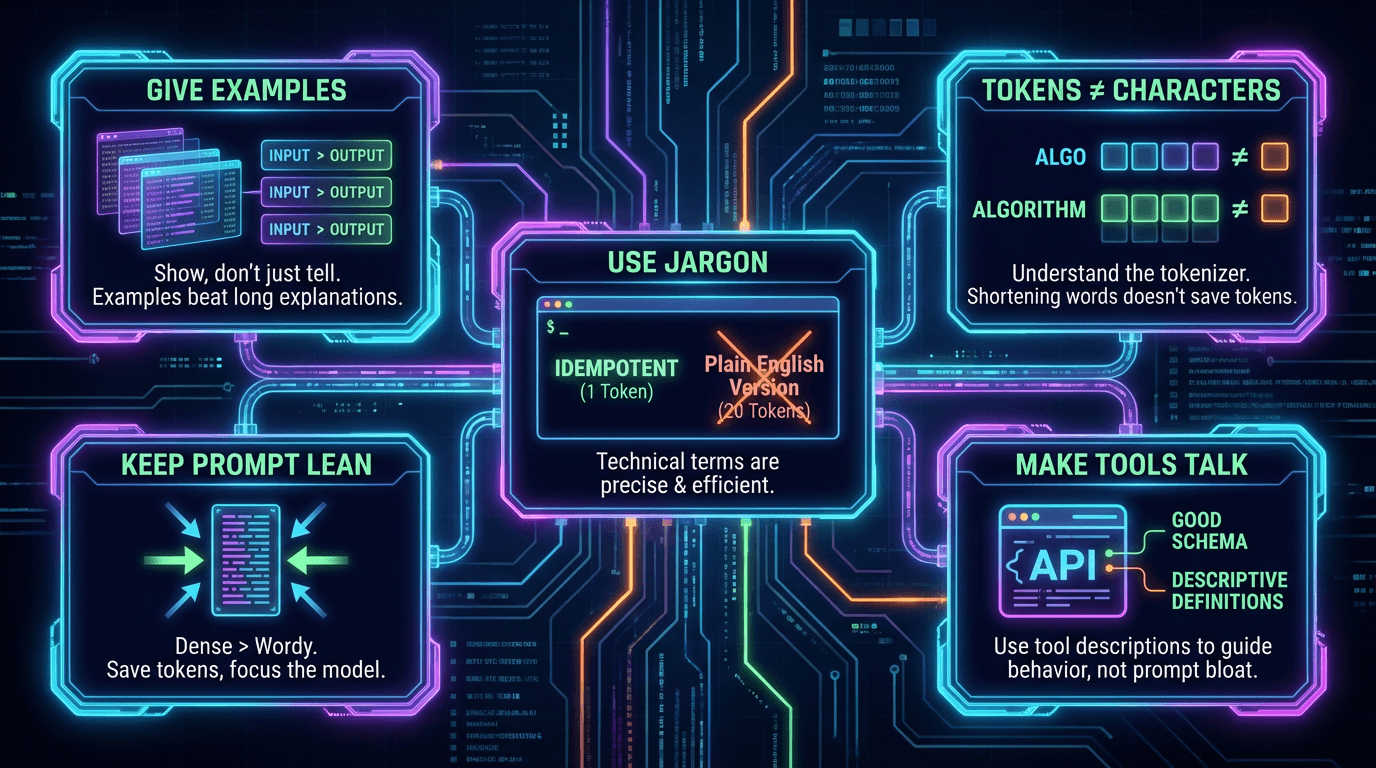
Give examples. Then more examples.
LLMs are great at taking a few thorough examples and generalizing them to new situations. Examples beat long explanations every time. Show the model what good output looks like and it figures out the rest.
Keep your system prompt lean.
Don't bloat it with walls of text. Dense and packed is better than long and wordy. Every token in your system prompt costs money. eats into your context window. and can dilute the model's focus. Say more with less.
LLMs handle jargon well. Use it.
Humans prefer simple language. LLMs don't care. A technical term like "idempotent" is one token and perfectly precise. The plain English version of that same idea might be 20 tokens. When writing prompts be dense and technical. Save the simple language for your users not your model.
Bad. "Make sure that if you call the API multiple times with the same request it only has the effect once and does not duplicate anything."
Good. "Ensure idempotent API calls."
Same meaning. One is 25 tokens. The other is around 5. The LLM understands both equally well.
Tokens are not characters.
This is a common misconception. Tokens are the units LLMs actually read and write. One token is roughly 3 to 4 characters but it varies. Tokenizers split text by common patterns not by characters. So common words and technical terms often get their own single token no matter the length.
"algo" is 1 token and 4 characters. "algorithm" is 1 token and 9 characters. You don't save tokens by shortening words. You save tokens by cutting unnecessary sentences and fluff.

You can play with this yourself using OpenAI's tokenizer tool. https://platform.openai.com/tokenizer
Make your tools do the talking.
Instead of stuffing everything into the system prompt focus on making your tools descriptive. Good schema. Good descriptions. The LLM reads those too and they guide its behavior without bloating your main prompt.




